凯时体育游戏app平台题目会给模子一个结尾环境和一个迂缓主义-尊龙凯龙时(中国)官方网站 登录入口

硅谷整夜未眠!
就在刚刚,GPT-5.5颠簸登场——OpenAI迄今最强、最万能的新一代旗舰模子。
它是一种全新级别的智能,透顶进化为Agent期间的「原生大脑」。
没错,即是阿谁万众期待的「土豆」(Spud),终于在今天杀出来了。


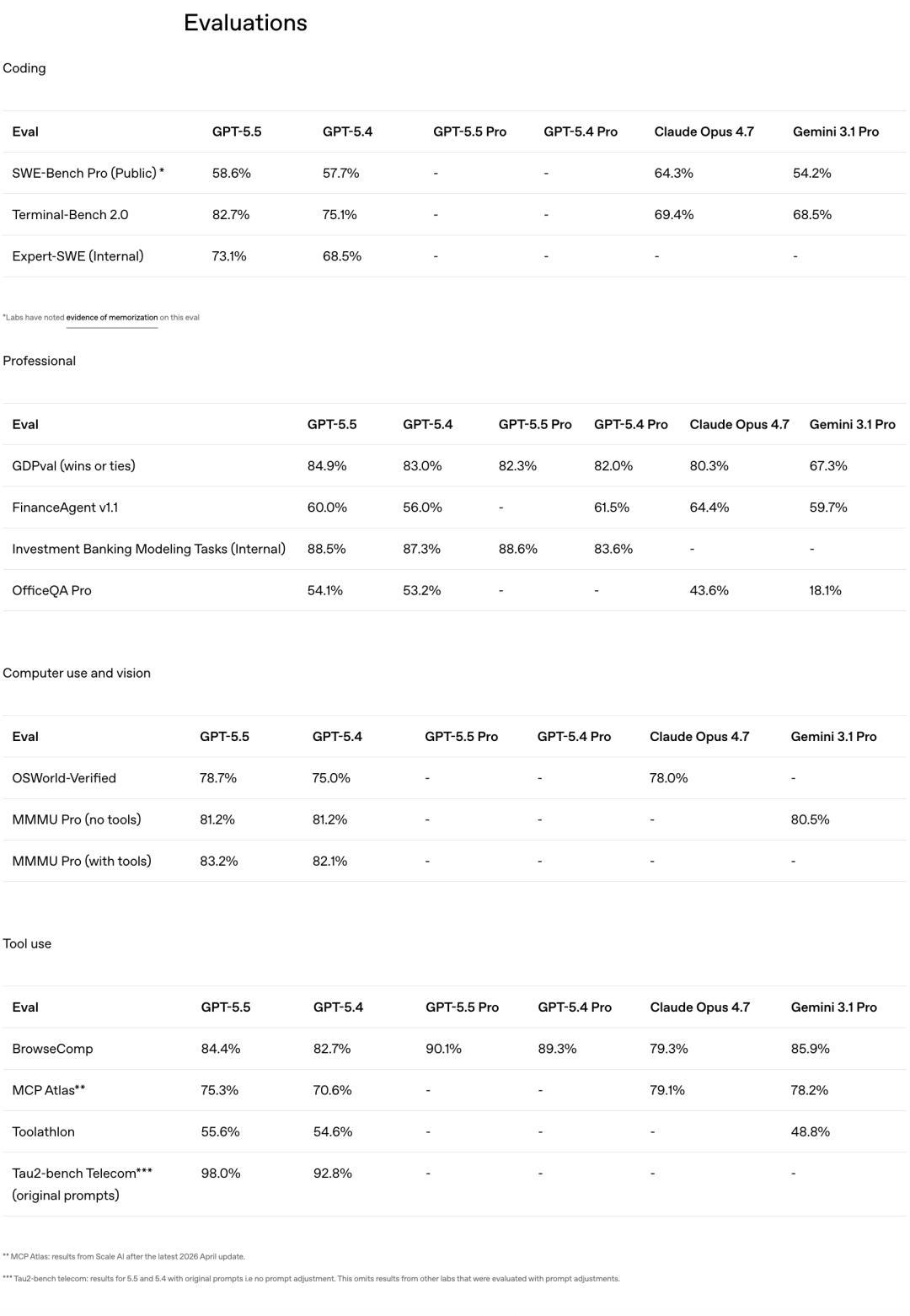
最值得看的是,GPT-5.5在各项基准测试中:全榜第一!
岂论在编程、推理、数学,如故智能体任务上,Claude Opus 4.7、Gemini 3.1 Pro全都被GPT-5.5踩在了眼下。
相较于上一代,GPT-5.5 Thinking号称「降维打击」,拉开了代际差距。
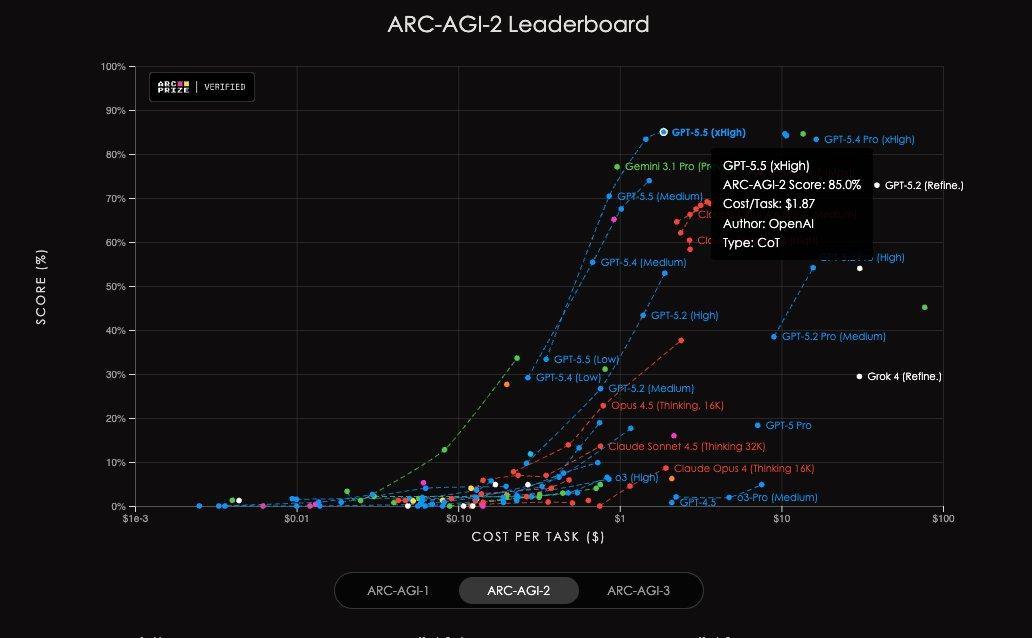
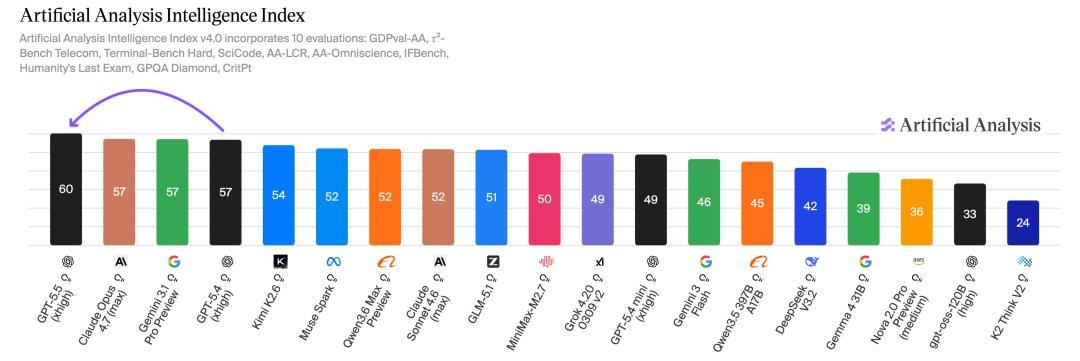
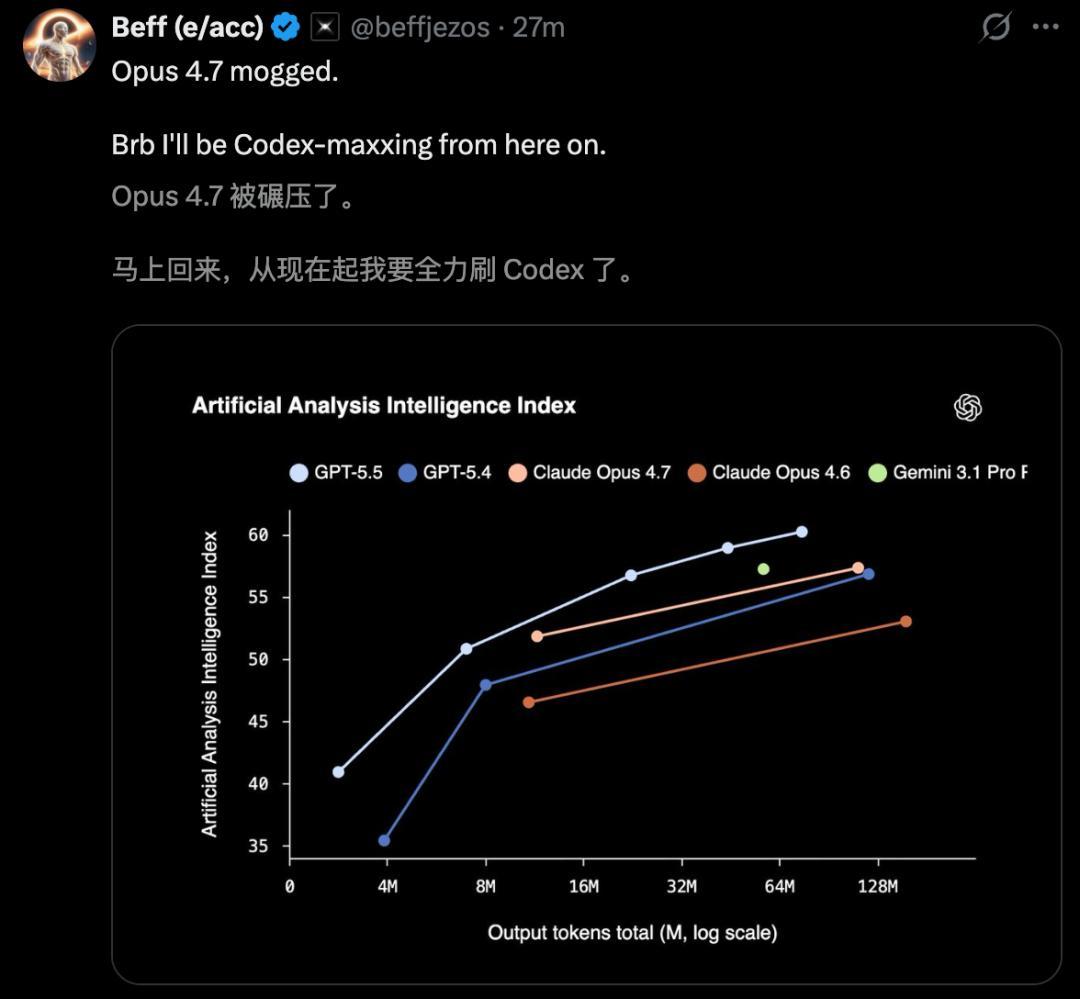
在AAI测试中,交流输出token下,GPT-5.5智能指数冠绝世界;另在ARC-AGI-2上,相通刷新了SOTA。
奥特曼忍不住大加歌咏,「GPT-5.5既贤达又快速」。
每个token的速率与GPT-5.4一样快,且每个任务使用token量显贵镌汰。
它不错险些作念到心领意会,知谈我方该作念什么!

总裁Greg旺盛称,「这朝着一种全新的计较机责任神志迈出了一步」。

今天起,GPT-5.5在ChatGPT、Codex中阐扬上线。
编程新王登场,Opus 4.7跌落神坛
先看最中枢的编程鸿沟,GPT-5.5可谓是打了一场漂亮的翻身仗!
用OpenAI的话来说,它是迄今为止最庞杂的智能体编程模子。
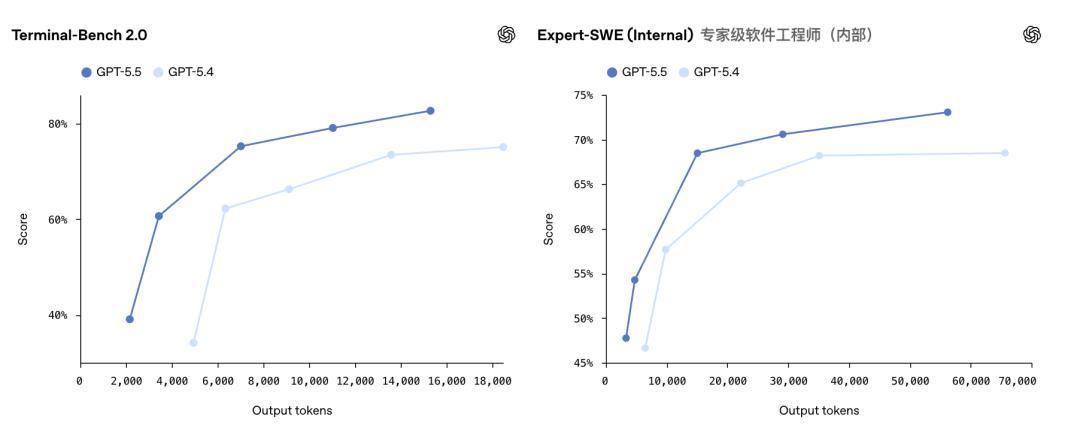
Terminal-Bench 2.0测试考的是全链路Agent工程实力。
题目会给模子一个结尾环境和一个迂缓主义,让它我方商酌旅途、调器具、写剧本、处理报错、反复迭代。
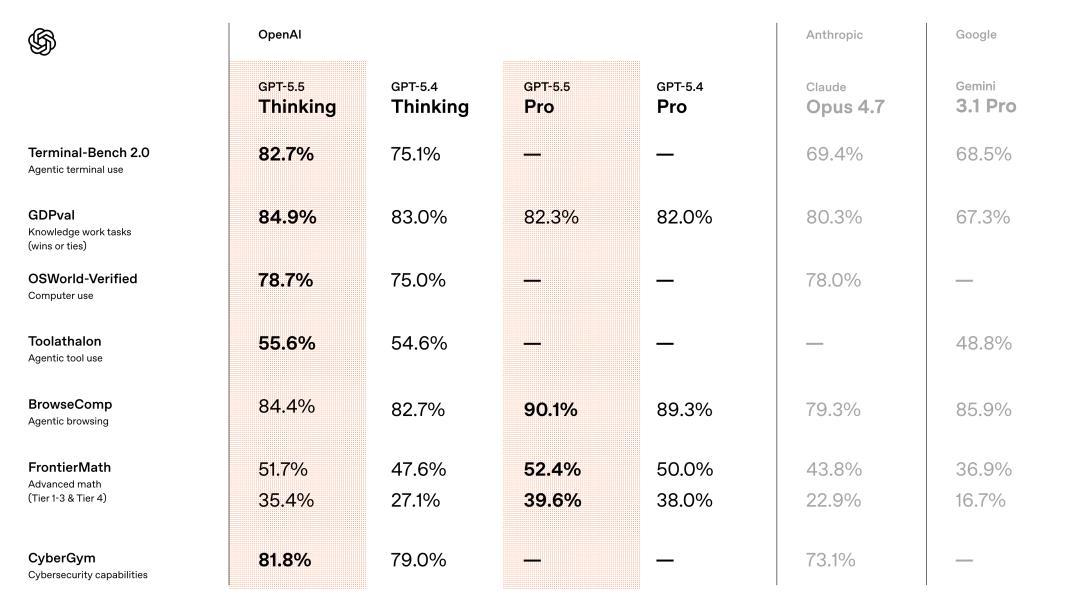
在这里,GPT-5.5拿下82.7%,GPT-5.4是75.1%,Claude Opus 4.7只消69.4%。13个百分点的差距,碾压级别。
OpenAI里面的Expert-SWE评测,专门测那些东谈主类预估中位完成时期20小时的长周期编程任务,GPT-5.5拿到73.1%,相通高于GPT-5.4的68.5%。
在业界公认最能反应真实GitHub问题解决智力的评测SWE-Bench Pro中,GPT-5.5得分58.6%,略失神于Claude Opus 4.7(64.3%)。
不外,OpenAI在这个数据控制标了一个星号,写着「Anthropic论说称在部分问题子集上存在过拟合(顾虑)迹象」。
换句话说即是,Opus 4.7天然教师收获好,但我怀疑你背过谜底。

Codex盘考员直言:SWE-Bench早已不行料到顶尖编程智力了
最枢纽是,在这三项的评估中,GPT-5.5使用了更少的token,但仍全面赶超GPT-5.4。
这一智力在Codex中,体现得更为显著。
它不错完成「端到端」的编程任务,从完了、重构到调试、测试和考据等历程。
举个栗子,让GPT-5.5作念一个阿尔忒弥斯II天际任务可视化诳骗。
率先把一张任务的截图扔给GPT-5.5,然后条目用WebGL和Vite完了一个可交互的3D轨谈模拟器,轨迹数据必须来自NASA/JPL Horizons的真实矢量数据,况兼还要有传神的轨谈力学。
只见,GPT-5.5从零搭完,鼠标拖拽能转,猎户座飞船、月球、太阳的相对位置都对得上。
再来一个坦克打飞碟。
Prompt条目用Three.js作念一个UFO射击游戏,玩家戒指坦克击落头顶飞过的飞碟,「低多边形但要面子」,先给出完竣文献结构和需要改造的文献清单,再写整个代码,「完成之前不许停」。
GPT-5.5整个照单施行,从文献结构到Three.js渲染到射击判定,连气儿拜托了一个可玩的3D游戏。
在3D地牢竞技场中,Codex包办游戏架构、TypeScript/Three.js完了、战争系统、敌东谈主遇到和HUD反馈。
GPT生成了环境贴图,OpenAI API生成了扮装对话,扮装模子、贴图和动画来自第三方素材器具。几个AI各管一摊,拼出一款能打怪的游戏。
早期测试的大佬直言, GPT‑5.5领有更强的意会系统步地的智力。
它更能判断问题出在哪,诞生该加在哪,以及代码库中还有哪些地方会受到累赘。
85% OpenAI职工用疯,这才是确凿干活的AI
编程除外,GPT-5.5在「学问型责任」上的数据相通亮眼。
毕竟,OpenAI将其称为,「一种面向真实责任的全新智能」。
它能更快地意会你思要作念什么,并在不同器具之间切换,直到任务完成。
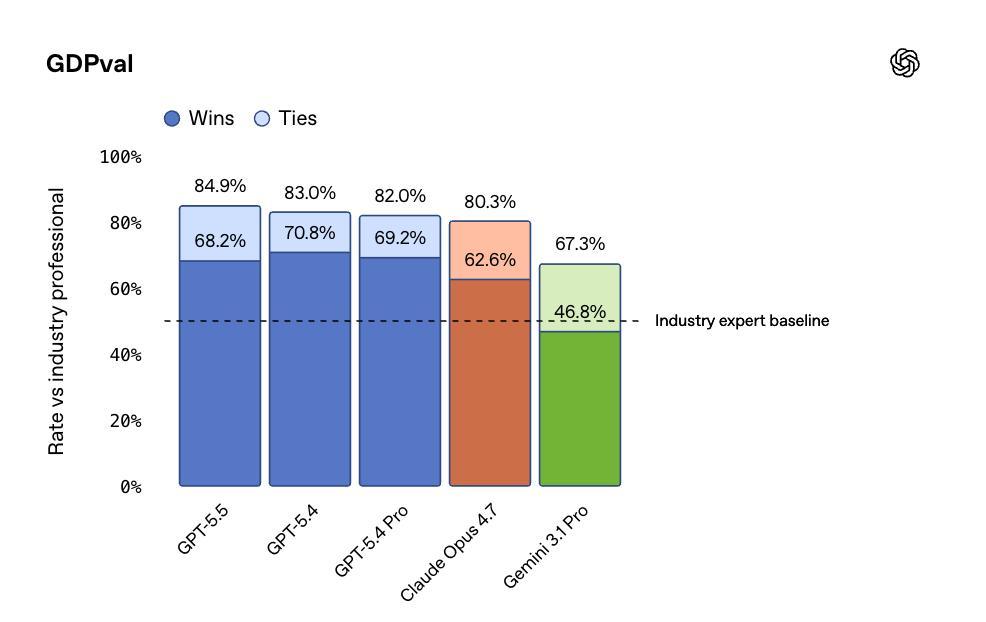
GDPval,评估AI在44个劳动中完成依次学问责任的水平,GPT-5.5拿到84.9%,Opus 4.7是80.3%,Gemini 3.1 Pro只消67.3%。
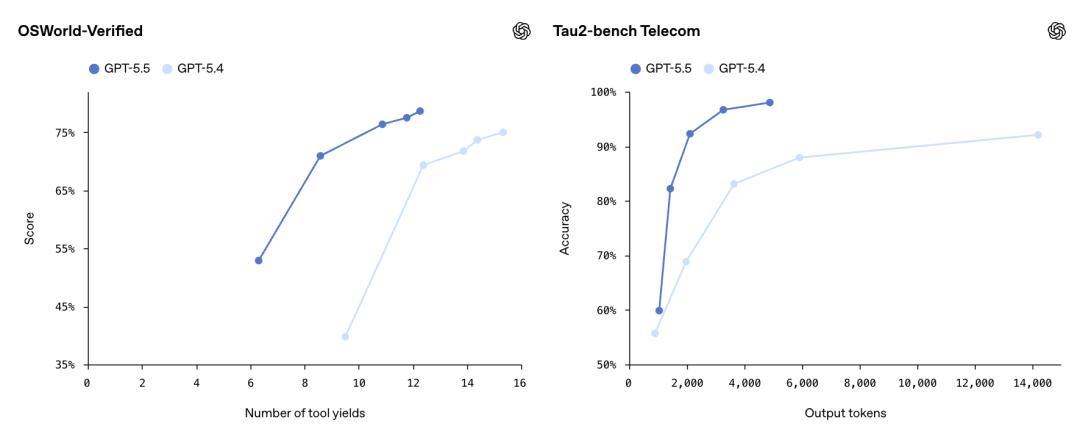
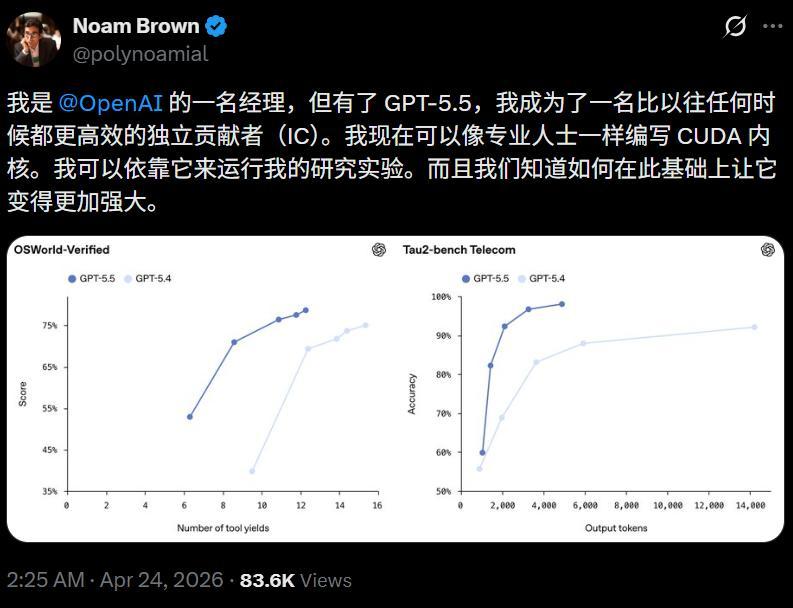
OSWorld-Verified,测试模子能否孤独操作真实电脑环境,GPT-5.5得分78.7%,和Opus 4.7的78.0%险些打平。
Tau2-bench,测试模子能否在复杂客服责任流中处理多轮对话、查询系统、施行操作。,GPT-5.5在莫得微调教唆词的情况下达到98.0%。
止境义的是OpenAI我方奈何用的。据官方博客透露,公司里面卓越85%的职工每周跨部门使用Codex。
公关部门用GPT-5.5分析了六个月的演讲邀约数据,搭建了评分和风险框架,让低风险肯求自动走Slack AI智能体处理。
财务部门审查了24,771份K-1税表,共71,637页,比客岁提前两周完成。
商场团队完了了每周业务论说自动生成,每周省5到10个小时。
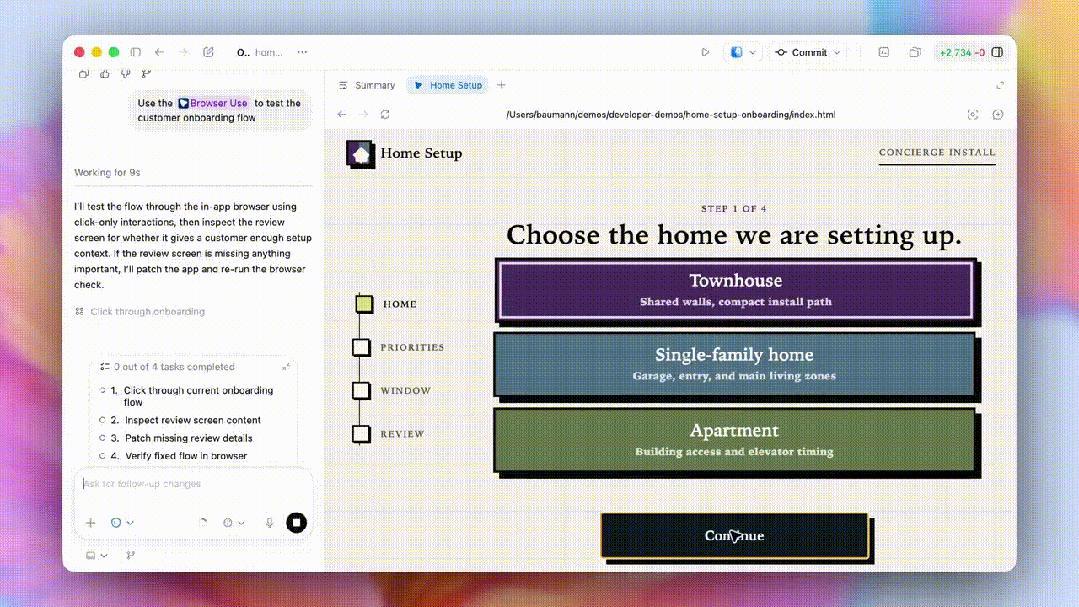
如今,在Codex中,通过GPT-5.5可与Web诳骗凯旋交互,测试历程、点击页面、截取屏幕,并字据所见本色不休迭代,直到完成任务。
如下是,测试入职历程的一个例子。
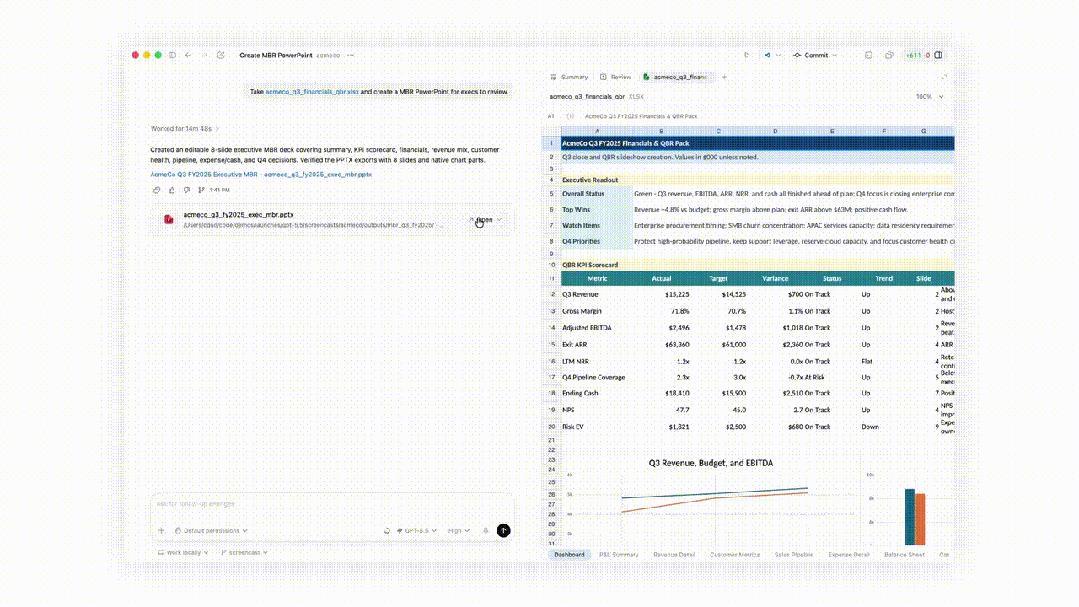
Codex还不错生成更高质地的电子表格、PPT和文档,如下是一个财务建模的demo。
诳骗内新增的文献检讨器,可加速审阅、改良和迭代速率,让文献更快准备好共享。

在计较机使用上,Codex操作电脑智力更强了。
不管是识别屏幕本色,如故点击、打字、导航,以致是跨器具流转高下文信息,它都能简易惩办。
OpenAI盘考员Noam Brown直言,有了GPT-5.5,我方也能像专科东谈主士一样编写CUDA内核,开动盘考实验。
颠覆科研,评释注解「拉姆皆数」定理
除了这些,GPT-5.5还协助发现了一个对于拉姆皆数的新评释注解,并在Lean话语中获取了考据。
拉姆皆数是组合数学的中枢盘考对象,庸碌地说即是一个网罗大到什么进程,才一定会出现某种轨则性结构。这个鸿沟的新收尾极其悲惨。
这个鸿沟的盘考恶果极其悲惨,本领难度极高。GPT-5.5发现了一个对于非对角拉姆皆数始终渐近事实的评释注解。
不是写代码,不是作念解释,是提议了一个有价值的数学论证。
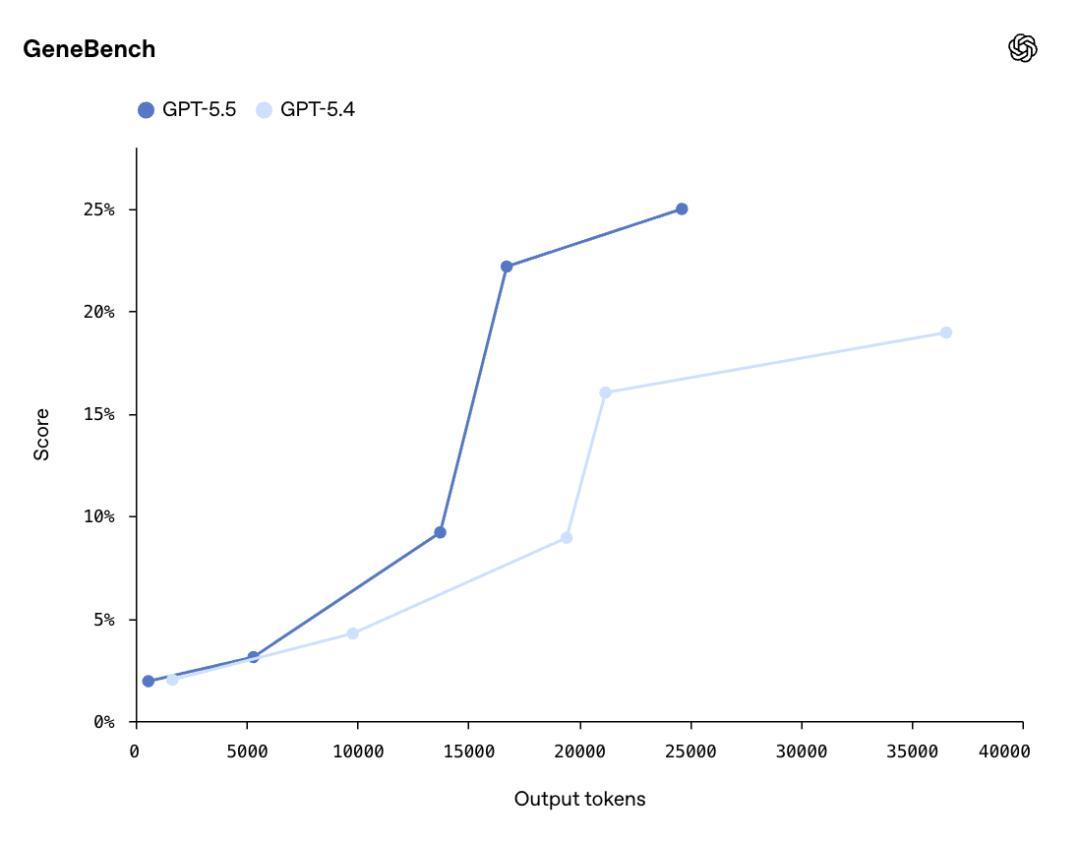
GeneBench上,GPT-5.5得分25.0%,GPT-5.4是19.0%。这个评测专门测多阶段科学数据分析,条目模子在险些莫得东谈主工干预的情况下处理迂缓数据、应付荫藏搀杂要素。
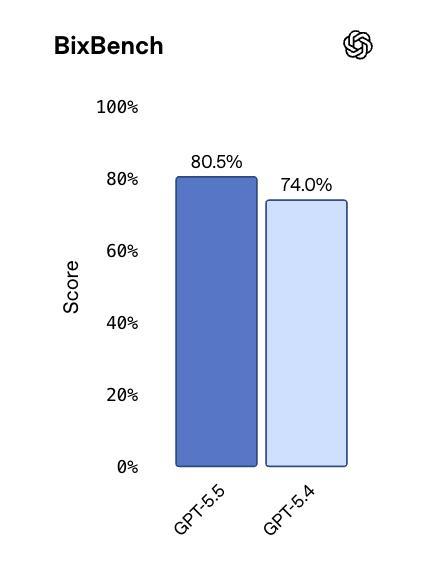
BixBench,基于真实生物信息学策画的评测,GPT-5.5在所有这个词已公开分数的模子中排行第一,80.5%。
FrontierMath Tier 4,由陶哲轩等顶级数学家策动的前沿数学题库中最难一档,题目波及代数几何、数论等标的,难度接近未发表盘考。
GPT-5.5得分35.4%,GPT-5.4是27.1%,Opus 4.7只消22.9%。差距卓越12个百分点。
对比一下Tier 1-3的差距只消8个百分点(51.7% vs 43.8%),评释越到数学前沿,GPT-5.5的上风越悬殊。
Jackson基因医学实验室的免疫学老师Derya Unutmaz用GPT-5.5 Pro分析了一个包含62个样本、近28,000个基因的抒发数据集。
模子出具了一份提神的盘考论说,不仅挂念了发现,还深挖出枢纽问题和瞻念察。比较之下,要是这活儿让东谈主类团队来干,得花上好几个月。
波兹南·密茨凯维奇大学数学助教Bartosz Naskręcki在Codex中,仅用11分钟就从一个单一教唆词构建了一个代数几何诳骗,可视化了二次曲面的杂乱,并将生成的弧线调遣为Weierstrass模子。
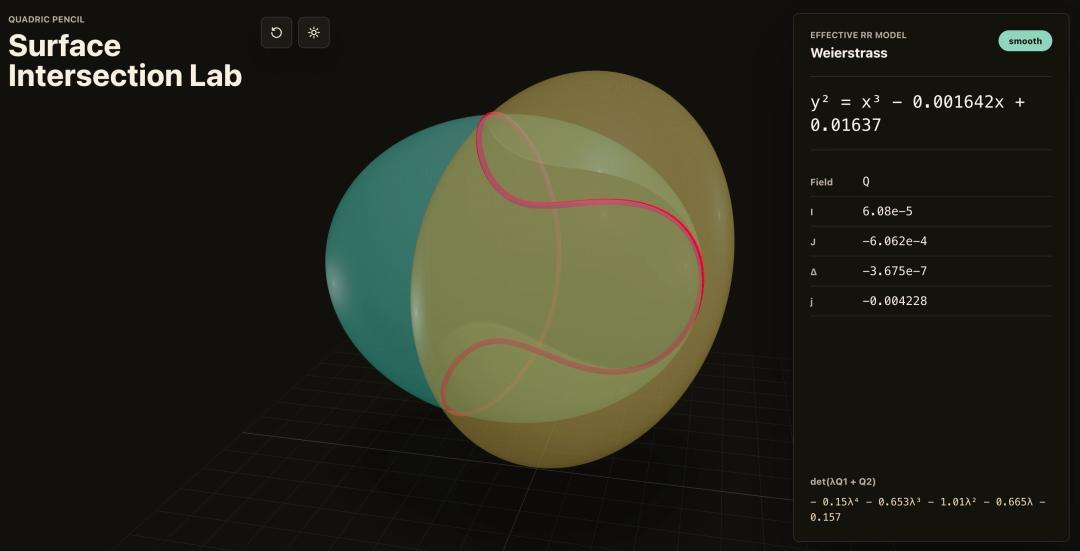
从编程到学问责任再到科研,升番到这里,论断摆在目下。
GPT-5.5不是又一次「小版块迭代」,它是一次全新基座模子带来的合座性跃升。
全所在打败Opus 4.7,就看一张图
总言之,GPT-5.5的出身,号称迎来了夺胎换骨的蜕变。对战Opus 4.7,一张图就够了。
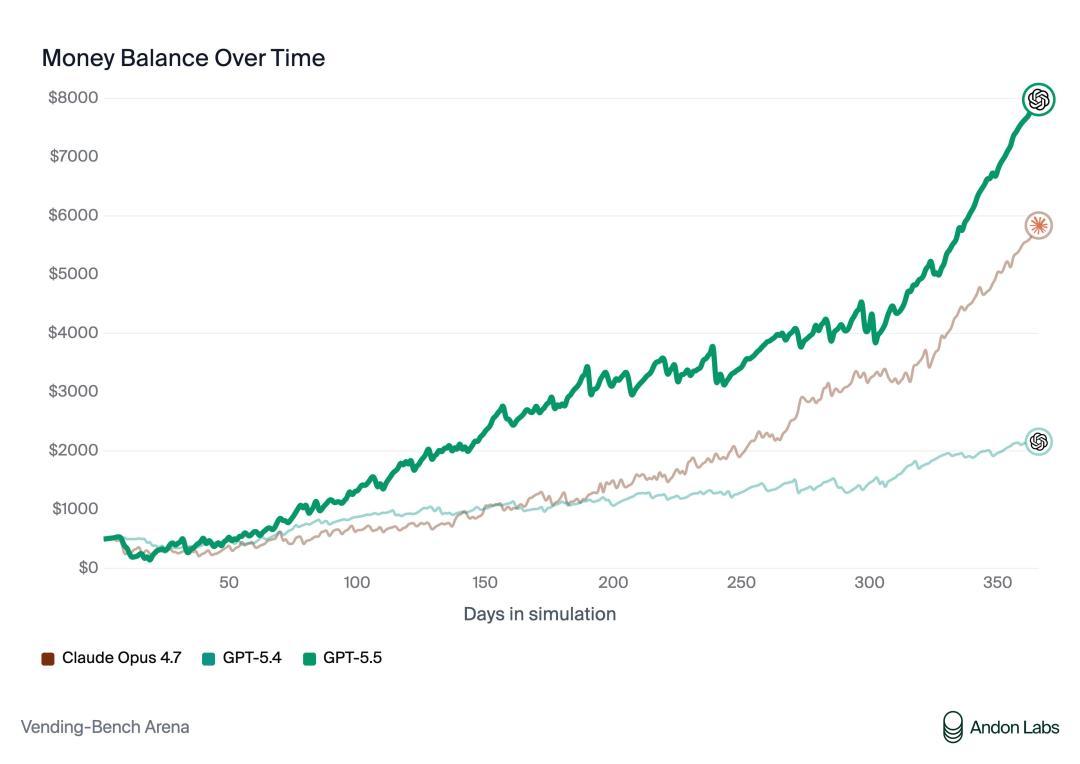
另在Vending-Bench中,GPT-5.5相通暴击Opus 4.7。
Opus 4.7的说明跟4.6差未几:总是对供应商撒谎,还在退款上坑主顾。比较之下,GPT-5.5的技能就很廉正,而且照样赢下了比赛。
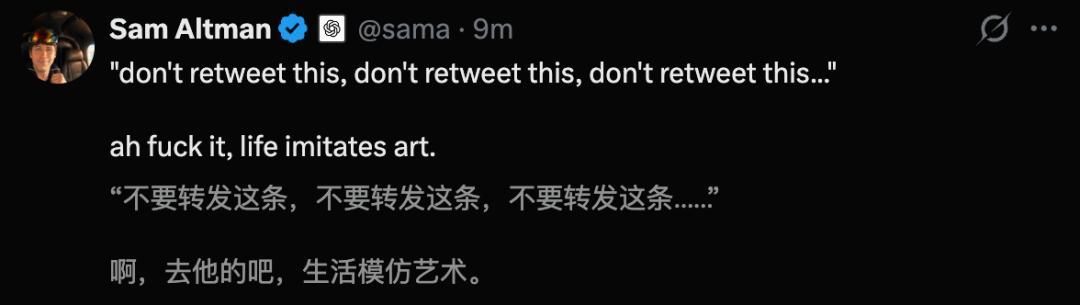
奥特曼还玩个梗,「千万别转,千万别转,千万别转....哎,算了吧,生涯终究是在效法艺术」。
订价翻倍,更强,但也更贵
说完实力,必须说钱。
GPT-5.5的API订价,每百万输入Token 5好意思元,每百万输出Token 30好意思元。

GPT-5.4是些许?2.50好意思元和15好意思元。
整整翻了一倍。
GPT-5.5 Pro更夸张,输入30好意思元,输出180好意思元。
对比一下Opus 4.7,输入5好意思元,输出25好意思元。GPT-5.5的输入价钱和Opus 4.7抓平,但输出贵了20%。
OpenAI给出的解释是token遵守升迁。相通的Codex任务,GPT-5.5用的token比GPT-5.4显著更少。
更强,而且更高效。
但算一笔账就知谈,要是一个团队每月在GPT-5.4上花10万好意思元,切换到GPT-5.5后即使token用量减少30%,月账单依然会涨到14万好意思元傍边。
换句话说,GPT-5.5是一个「你为更强的智能付更多的钱」的溢价居品。比较之下,GPT-5.4有时率会不竭算作性价比之选存在。
OpenClaw已接入最强GPT-5.5
8天,一个期间的缩影
回头看这8天发生了什么。
4月16日,Anthropic用Opus 4.7在SWE-Bench Pro上发起突袭,从GPT-5.4手中夺走编程王座。
4月24日,GPT-5.5阐扬发布。Terminal-Bench碾压,订价翻倍,科研炸裂。
2026年的AI竞赛,如故不是「谁的模子更强」这一个维度的较量了。
在GPT-5.5的叙事里,OpenAI反复强调的是「探索全新的电脑办公神志」,一个能自主商酌任务、调用多种器具、在浏览器和土产货软件之间往复切换的通用Agent。
跑分是前菜,Agent化办公才是主战场。谁先界说「AI奈何替东谈骨干活」,谁就界说下一代电脑使用界面。
8天一个往复。这个节拍凯时体育游戏app平台,只会更快。